CQRS in a Relational Database via Slick
CQRS - Command and Query Result Segregation - is a useful tool for systems where the inbound data is a stream of events that behave like telemetry, and parts of the system need some coherent, more complex view of state. With CQRS the system records the events in a list as they flow in. Later, when the system needs a coherent understanding of state, it examines the events and assembles a self-consistent structure. "Command Responsibility" comprises the mechanics to record the events quickly and with minimal blocking - especially minimal locking. "Query Responsibility" absorbs the complexity and cost of assembling a coherent state to meet the reader's needs.
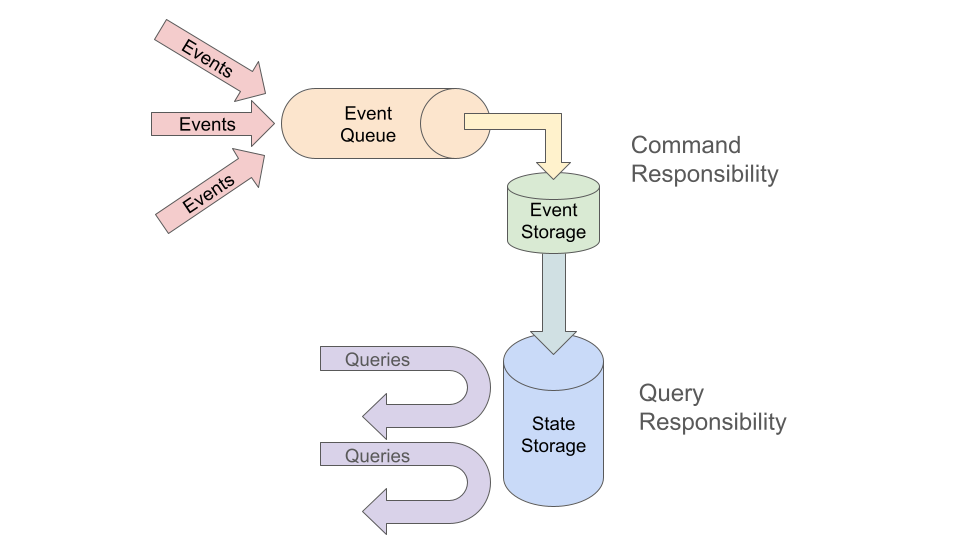
This arrangement removes the bottleneck of processing the data as it comes in by moving the work of refining the data to some time before it will be used. If the data is used in multiple ways then each use can have its own specialized refinement to match that use's queries.
In distributed system terms CQRS defines the first, most time-dependent map on the event stream to "just store the events," delays and separates that from a complex reduce of "convert the events to something useful," then enables efficient queries of the structure that best matches the end-use.
The best candidate systems for CQRS are systems where events arrive out-of-order; that's pretty much any system with distributed, changing state. It also includes every system that uses message-oriented middleware; even with best-effort configurations to keep messages in-order they can still arrive out-of-order. Within a single computer: parallel threads can execute in strange orders, "happens before" rules are softer than we might wish, and computer clocks are notoriously bad. Sometimes a program running on a single computer can benefit from CQRS.
Systems where updates come in rapidly benefit from the efficient processing of writes in the "Command Responsibility." The "Command Responsibility" writing of updates is relatively straight-forward to replicate across threads and even distributed servers, so it scales up easily with the volume of data flowing in. Systems that process and use the data for different purposes benefit from the separation of "Query Responsibility." Each can have its own on-demand processing of the stored events. The stored events naturally provide an audit trail and the ability to replay the events. Replaying the events to debug a distributed system is invaluable, perhaps the most powerful "Query Responsibility" feature.
I'll be pulling examples from my work at HMS Catalyst on SHRINE (the Shared Hospital Research Information Network E) - a system that allows a researcher at any hospital to query for counts of patients with similar characteristics at all the hospitals in the network. The core idea behind SHRINE is that patient records never leave the hospitals; every hospital runs a researcher's query and reports a count of patients to the network.
When I started on SHRINE it used a web API call that fanned out into a layered system of slow and unreliable patient data servers. That initial web API call might take as long as five minutes to finish - with no feedback to the researcher. For usability five minutes is a coffee break; the researcher might not come back. For normal http connections on the internet five minutes is "probably just broken." SHRINE 2.0+ shows incremental query progress and results as soon as they are available from each hospital. Patient counts for simple queries from the fastest sites show up in a second or two - a usability breakthrough.
SHRINE version 2.0 and onward have a common currency of case classes that represent queries, results, researchers, nodes (usually hospitals), and the SHRINE network itself. (See future blog article after I write it.) The events are changes to these structures.
We started recording events in a simplified "Command Query" style in SHRINE 1.19 because one customer required an audit trail. We expanded it to a CQRS-style local-to-the-user forward cache in SHRINE 1.21 to improve performance. That showed us our system did need to handle distributed state better; SHRINE 1.23 demonstrated the value of incremental updates of the distributed quereis in progress - via message-oriented middleware. In SHRINE 2.0 we adopted CQRS fully and ran it with no significant change to the code for five years. One large network ran SHRINE 3.1 for three years - with no update at all.
Do Not Use CQRS Unless You Need It

Li Haoyi's blog entry "Strategic Scala Style: Principle of Least Power" introduces CQRS with "Don't use Event-Sourcing/CQRS unless you know what you're doing." https://www.lihaoyi.com/post/StrategicScalaStylePrincipleofLeastPower.html#immutability--mutability If you haven't read that article - go read it now. It's amazingly good general advice. Then understand why I've got references to Jon Stone's The Monster at the End of This Book, and that what follows is likely not good advice.
If your system's state is immutable - it creates things but never changes them - then you really don't need CQRS. Just record what you create to unpack later.
If state will only change in a slow and sedate fashion on a single thread then you can use something less intense like traditional database transactions. Be aware that database transactions often do not have the ACID properties we wish they did. In a small, slow, sedate, centralized system database transactions will probably be fine. When you put that central database under pressure, with changes coming in concurrently, then expect trouble. With too much locking things will slow down; with too little the system can lose coherency - or even data.
CQRS Creates A List of Events To Replay
The heart of CQRS is list of events. Some parts of the system emit events. "Command Responsibility" stores events but never changes them. Later "Query Responsibility" replays the events to construct state. Replay the events - in order - to reproduce the state.
You could store the events in a concurrent in-memory structure so long as you aren't concerned with what happens after the process terminates. A simple database table (time stamp and the event structure) can work reasonably well. NoSQL list databases like CouchDB and DynamoDB are even easier to set up than a database; they are possibly overkill for the "Command Responsibility" but work great.
The resulting CQRS system relies on the event time stamps being solid enough for "in order" to work in your system. That pretty well describes what we did for SHRINE 1.21's forward cache; we made a simple database table to record the changes in state, then used the timestamps to generate the states we showed to the researchers. It worked well in a low-traffic network of four hospitals.
Using this event list for a network of four dozen hospitals, many more active researchers, and message-oriented middleware showed us that the timestamps were not good enough to rebuild the state in this busier environment. We had to ruthlessly take advantage of SHRINE's particulars to reassemble the state to resolve conflicts when the time stamps didn't work out. Each new bug we discovered resulted in a new condition to check. The cyclomatic complexity of the logic to reproduce the state started to fold on itself.
Sometimes You Need CQRS (Sometimes It Won't Be Enough)

CQRS is particularly good at making a coherent, self-consistent view available in the chaos that is distributed computing. Observations of time in computing systems are staggeringly horrible.
You might recall "The Barn Pole Paradox" from relativity physics. Computing is worse.
The resolution of the paradox is to split "Is the pole in the barn?" into two events - "the front of the pole exists barn" and "the end of the pole enters the barn" - then twist them through the Lorentz transform to show that their order can swap based on the observer's frame. (Muppets demonstrating that paradox would be fitting.) At least the geometry of the universe holds the observers to some rules.
Observation in distributed systems - at the bottom of Earth's gravitational well, not moving at significant speeds - don't usually have significant relativistic effects, but they do have:
Discrete time - Different things can happen at the exact same clock time
Processors that run faster than the clock resolution - My laptop clock has an API resolution of one nanosecond, but has processors running at four GHz. About four things should happen in the same tick on each core
Concurrently-running processors - Many things could happen at the same time on different cores. My laptop has 12 cores.
The actual resolution of the operating system's - and JVM's - times are more often on the order of microseconds.
The program reading a clock takes some poorly controlled amount of time.
Computer clocks are temperature-sensitive.
I work mostly on Java virtual machine systems. The JVM's nanosecond clock counts up from an arbitrary point starting when the JVM process starts. It's handy for controlling frame-rate in a video game loop, but would need to be pinned to the operating system's clock for anything off-board.
The JVM's API resolution for the OS' clock is in milliseconds.
The OS's clock resolution might be finer, but in older operating systems may only have accuracy of 30 ms. (One really old OS will sometimes jump backwards 10s of ms!)
The ntp protocol can keep distributed computers' clocks to within about 10 ms on stable LANs, and maybe 100 ms on networks you wished worked better.
ntp can speed up or slow down the clock, especially just after start-up.
The system admin can set the clock to arbitrary values.
A network call across loopback takes at minimum 10s of ms.
Writing a local file takes 10s of ms. Memory buffers makes this highly variable.
http calls across a LAN takes at minimum ~100 ms.
https calls across a WAN takes at minimum 100s of ms.
Reliable message-oriented-middleware (MOM) calls get their reliability by adding more network and file system calls.
Messages in MOM systems may arrive out-of-order for any number of reasons.
MOM also adds queues to the works; messages may sit in queues before they are processed - possibly for days.
MOM's zero-or-more message delivery promise means that a client may receive the same message more than once.
If your system is about changing state across distributed computers then you need some way to build a reliable system around all of that. CQRS is a good starting point, but may not be enough.
The Art Of Compromise: CQRS, But Storing State Changes
SHRINE 1.23 was a skunk-works experiment to show the researchers progress updates as queries moved through the network. We replaced the long, slow, layered web API calls with message-oriented middleware queues to support asynchronous reporting and gain reliability. Queries and results gained more observable events. That fidelity interacted badly with the low quality timestamps; we needed even more cyclomatic complexity to recreate the state.
"Complexity is your Enemy" - Lee Haoyi . We needed some way to limit the complexity of the logic . SHRINE had compute power and IO bandwidth to spare. (The most significant bottleneck in SHRINE - by two orders-of-magnitude or more - is in the patient data source. We could never change that.) The events in SHRINE carry small changes to small pieces of state of progress through the network for a result. The distributed parts of the system that were emitting the events have valid - but possibly outdated - versions of the state. We could take advantage of that.
I took some inspiration from CouchDB/DynamoDB. For SHRINE 2.0 I decided to store state in CQRS style instead of storing simple events. I changed the message meanings from "events" to "proposed state updates" . If the previous state has not changed then SHRINE can safely apply the update. If SHRINE discovers the previous state had changed then some business logic kicks in to decide what to do with the update. For example if a successful result arrives in conflict with a failed result then SHRINE's logic chooses to take with the successful result (as a state after the failed result). Because each state is recorded the states can be replayed. The desired state transitions impose a best order without depending on the unreliable timestamps.
Storing state structures like this is a recommended practice for CouchDB/DynamoDB systems. ... That's not what we used.
More Art, More Compromise: CQRS - but Storing State - in a Relational Database

Really - if you can just use CouchDB, or DynamoDB, or something that fits your problem better than late-1980s relational database tables then stop reading, build your system, and go live a happier life. I recommended we store SHRINE's common currency data structures in DynamoDB or CouchDB, with a thin facade to just expose the calls SHRINE needed from either tool. My boss pointed out that our operations team had no experience with either system and were busy with higher priority projects. We needed to store everything in the relational database SHRINE already used.
Later Simon Chang - an amazing operations engineer - and I demonstrated SHRINE 2.0 running with AWS DynamoDB in a 24-hour hack-a-thon in 2019. We got it working in about 4 hours, built a demo with repeated 60-hospital simulated surge tests, had a good night's rest, then put together the presentation in the morning. It worked really well. (... until we burned through the DynamoDB free tier transaction allowance, half-way through showing it to the boss' boss after the party.)
You're Still Reading?
Let me see if I can talk you out of the mistake you are about to make by showing some of the code I wrote to get this working in SHRINE. (I guess it wasn't that bad, but we own some complex code when we could have just downloaded a library.)
SHRINE already used Circe to convert its common currency case classes into JSON to transmit in messages and http bodies. SHRINE already supported three brands of database via Slick; we use Slick to save us writing every bit of database code three times. I designed a standard table - and a standard case class trait - to support storing Circe-serialized case classes - using as few database-specific features as possible.
The case classes - at their simplest - look like this:
case class Researcher(
id:ResearcherId = ResearcherId.create(),
versionInfo: VersionInfo = VersionInfo.create,
userName:UserName,
userDomainName:UserDomainName,
nodeId:NodeId
) extends Versioned[ResearcherId] {...}
The itemVersion member in VersionInfo provides an order of states observed in SHRINE's modified CQRS system. (The protocolVersion field supports backwards-compatibility and the other fields are invaluable for debugging.)
case class VersionInfo(
protocolVersion:ProtocolVersion,
shrineVersion:ShrineVersion,
itemVersion:ItemVersion,
createDate:DateStamp,
changeDate:DateStamp,
) {...}
ItemVersion is just an Int value class:
class ItemVersion(val underlying:Int) extends AnyVal with ValueClass[Int]
If everything is working smoothly then the itemVersion should increment by one for each recorded change in state for a case class with a given id. SHRINE will insert a new row in a table in the database each time it observes a new state. When SHRINE needs to provide a most-up-to-date view of state it will select the row with the right ID and maxiumun itemVersion, then reconstitute the case class from that row's JSON .
def selectResearcherByIdIO(researcherId: ResearcherId): IO[Option[Researcher]] = {
//Select the row with the maximum itemVersion for the id
runIO(Researchers.allRows.filter(_.id === researcherId).sortBy(_.itemVersion.desc).take(1).result.headOption).
map( _.map(_.toResearcher)) //convert the JSON to a Researcher
}
Before SHRINE inserts the new row it checks that there's no row for that id with the itemVersion. If that's true then it inserts the new row:
tableCompanion.allRows.filter(r => r.id === row.id).filter(r => r.itemVersion === row.itemVersion).result.flatMap {
case Seq() => { // a row with this id and version does not exist yet
//insert the row only if it is the only row with this id and version
tableCompanion.allRows += row
}.map {
//expect insertCount to be 1
When SHRINE receives data out-of-order, but with the correct itemVersions then SHRINE simply inserts the late data's JSON in the table. The rest of the system can flow without worrying about things written out-of-order in the database.
When SHRINE detects a row with the same id and itemVersion then SHRINE does a simple check to see if the states match. If an identical state is already in the table then it's not a problem; something else wrote the data earlier - which can certainly happen with message-oriented middleware retries. If there's a difference in the JSON then this particular write lost a race. SHRINE's database code fails with an exception so that code with a broader context can decide what to do.
case alreadyExists => // at least one row with this id and version does exist already
// don't insert the row
// if the existing rows with this id and version are the same then this isn't a problem
if (alreadyExists.forall(_ == row)) DBIO.successful(None)
// However, this is a problem if the new row is different from the others
// Due to the transaction this should only happen if some other row was written outside this method
else DBIO.failed(ItemVersionRaceLostException[I, V, R](item, row, alreadyExists))
The whole works starts with a write operation to an auxiliary table that exits solely for locking. This lock prevents multiple inserts from happening concurrently on data in the same table. I could have gotten more throughput with a row-per-ID and corresponding lock. I thought of it late, and SHRINE preformed very well without that optimization.
//increment the table version and isolate this transaction
incrementTableVersion(tableCompanion.tableName).flatMap { _ =>
In case you're not convinced to just use CouchDB or the like - here's the full, unedited method, with four generics to fill in. It's not the worst code, but requires a lot of supporting bits to make work. Converting Slick's DBIOs to cats effects IOs wraps around this call. Additional code in the IO layer adds business logic to decide how to resolve conflicts shown by ItemVersionRaceLostExceptions.
private def upsertItem[
I <: Id: ClassTag, //Needs the ClassTag to let I survive erasure
R <: Row[I],
V <: Versioned[I],
Items <: ItemTable[I,R]
](
item: V,
tableCompanion: ItemTableCompanion[I,R,V,Items]
): UpsertItemType[V] = {
val row = tableCompanion.itemToRow(item)
implicit val IdColumnType: JdbcType[I] with BaseTypedType[I] = MappedColumnType.base[I, Long](
id => id.underlying,
long => tableCompanion.longToId(long)
)
//increment the table version and isolate this transaction
incrementTableVersion(tableCompanion.tableName).flatMap { _ =>
// Find all the rows with the same id and version number
tableCompanion.allRows.filter(r => r.id === row.id).filter(r => r.itemVersion === row.itemVersion).result.flatMap {
case Seq() => { // a row with this id and version does not exist yet
//insert the row only if it is the only row with this id and version
tableCompanion.allRows += row
}.map {
//expect insertCount to be 1
case ic if ic == 1 => Some(item)
case insertCount: Int => throw HubDatabaseAssertException(s"""insert into ${tableCompanion.tableName} returned $insertCount, not 1 as expected""") // ic == 0 would mean nothing was inserted. I don't think ic > 1 can happen
}
case alreadyExists => // at least one row with this id and version does exist already
// don't insert the row
// if all the existing rows with this id and version are the same then this isn't a problem
if (alreadyExists.forall(_ == row)) DBIO.successful(None)
// However, this is a problem if the new row is different from the others
// Due to the transaction this should only happen if some other row was written outside this method
else DBIO.failed(ItemVersionRaceLostException[I, V, R](item, row, alreadyExists))
}
}
}
Examining the generated SQL showed that almost everything in this method happened within one prepared statement in the database. Most of the time to make the call is connection and transmit overhead to get out of the JVM and into the database's process. It's pretty efficient.
All-in-all this worked very well for SHRINE 2.0 to SHRINE 4.3 - about five years of production use. That upsert() is probably the most involved method I wrote and didn't delete in SHRINE's codebase. It has the feel of a senior class project to teach us how something complex works. I'm happy it works well, but there are easier off-the-shelf tools to get CQRS working. It's something other people could use but probably shouldn't.